
Listify in Haskell (Part I)
I’m rewriting Listify in Haskell, with a few changes. As a reminder, the original Listify (henceforth Listify-js) is a web app that scrapes the BBC radio website for tracklisting and program schedule information, and allows users to browse these tracklists and create Spotify playlists from them. The new version (henceforth Listify-hs) aims to build on this by introducing VCR-like functionality (or TiVo Series Link for the young’uns among you) of being able to ‘follow’ a show and have each episode’s corresponding playlist delivered to your Spotify account, as scheduled.
I’m rewriting it for a number of reasons:
- The original version was written in NodeJS/Express, and I’m finding that JavaScript code hard to maintain over time.
- I’m using it as a learning exercise through which to better understand certain Haskell concepts.
- There are parts of the application that I think are better suited to being implemented with Haskell (e.g. web scraping), and as an engineer one should always looks for better, simpler, more elegant solutions.
This is the first in a short series of blog posts that I’ll write as I build the system. This first post covers the scraping component, but keep an eye out for future posts, and also follow the implementation here on GitHub.
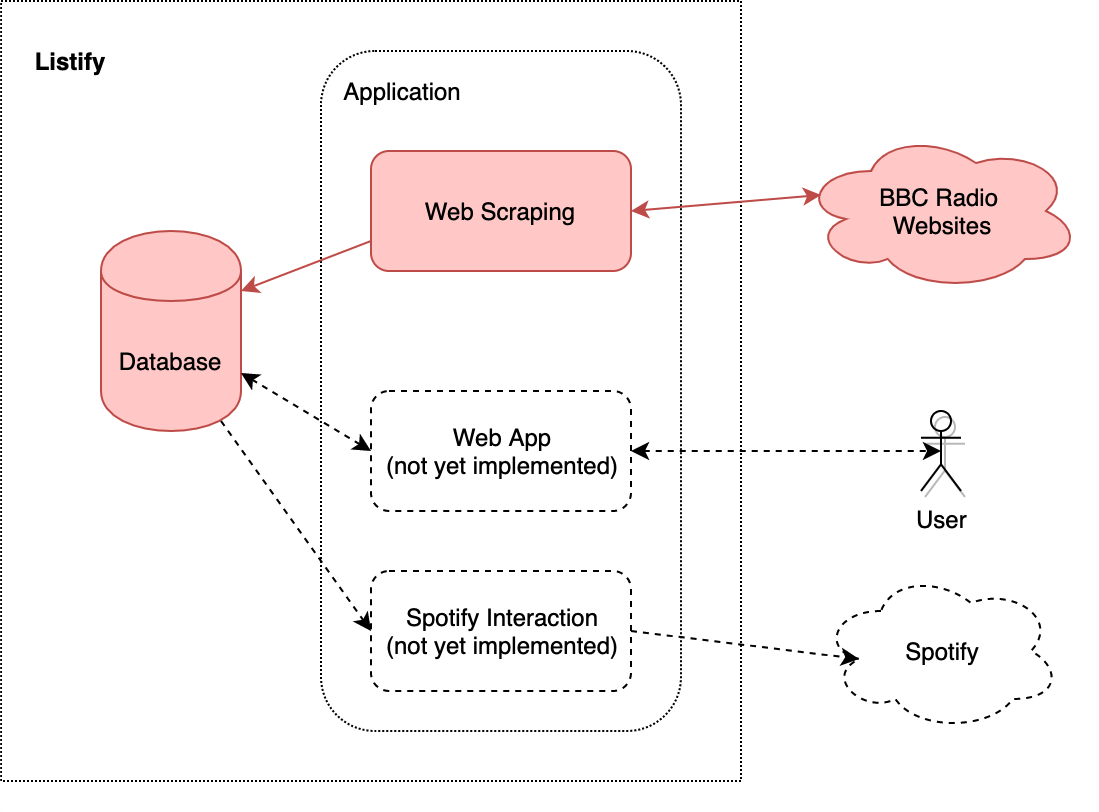
Overview
The purpose of this part of the system is to scrape playlist information from the BBC website (unfortunately there is no API available), and persist it to a database for later use. This is a batch process that will run daily. The components of interest are highlighted in red in the diagram below:
Project setup
I’m developing using the Atom text editor with the IDE-Haskell plugin.
The project is built using Stack, with dependencies defined in a Cabal file. Git commits are subject to CI builds on Travis, which also runs a small suite of HSpec integration tests.
The project structure/layout was inspired by this informative talk on how to structure larger Haskell projects, given at Haskell eXchange 2017.
The main file of entry to follow the code for the scraping component is here.
Scraping
The actual web scraping is done using the Scalpel library. Scalpel allows you to declaratively describe the scraping to be performed, resulting in more elegant code when compared to the original Listify-js implementation.
The central type in the Scalpel library is Scraper. The Scraper‘s job is to look certain HTML tags in a webpage that match some criteria, and return the contents therein. Scraper is made more useful by being an instance of (among others) two type classes: Applicative and Alternative.
Alternative
Alternative allows us to represent a choice of computation. We can use the <|> operator between two possible Scrapers that have different matching criteria, to have both criteria evaluated and return the combined result. This is useful when parsing HTML where there is some alternative or missing tags. For example, from here (simplified below), we may not always have an album tag, so we should check both ways (with and without):
playlistItemScraper :: Scraper ... Track
playlistItemScraper = hasAlbumScraper <|> noAlbumScraperApplicative
Applicative allows us to use multi-argument functions in a more general way, i.e. by applying them to values in a context. First, some background: the Applicative type class has less structure than Monad, but more than Functor. The fmap function in Functor allows us to apply a unary (single-argument) function to a value in a Functor context (by lifting that function into a Functor). For example, below we have the single-argument function (+3) - a section - and a value in the Maybe Functor, Just 3:
example :: Maybe Int
example = fmap (1+) (Just 3) -- results in 'Just 4'However, its more useful to be able to lift multiple-argument functions into a context. Monad supports this with the various liftMn functions (where n is the number of arguments the function takes). In the example below, we lift the binary (two-argument) function (+), using the liftM2 function, to the Maybe Monad:
import Control.Monad
example :: Maybe Int
example = liftM2 (+) (Just 1) (Just 3) -- results in 'Just 4'However, Monad brings excess functionality than what is required to solve just this problem of function application. Thats where Applicative comes in. By using the <$> and <*> operators from Applicative, we can lift multi-argument functions to an Applicative and then apply it to values in that Applicative context, respectively. Example below with the Maybe Applicative:
example :: Maybe Int
example = (+) <$> (Just 1) <*> (Just 3) -- results in 'Just 4'The scraping code makes use of this. For example we can write an expression like the one below (taken from here), which in my opinion is quite elegant (type signature simplified):
playlistItemScraper' :: Scraper ... Track
playlistItemScraper' = Track <$> artistScraper <*> titleScraper <*> albumScraperTrack here is a multi-argument data constructor (i.e. a function) whose type is: Text -> Text -> Text -> Track. The values artistScraper, titleScraper, albumScraper are of type: Scraper ... Text (think of this as a Text value in the Scraper Applicative context). The Track function gets lifted to the Scraper Applicative and applied to the artistScraper, titleScraper, albumScraper values.
For comparison, the Applicative expression above is the desugared version of the less tidy do-notation equivalent:
playlistItemScraper' :: Scraper Text Track
playlistItemScraper' = do
artist <- artistScraper
titl <- titleScraper
album <- albumScraper
return $ Track titl artist albumPersistence
The results of the scraping are persisted to a MySQL database, for later use by other components of the Listify application (coming soon). Interaction with the database is done via the mysql-simple library, created by the guy who literally wrote the book on how to use Haskell in the real world.
The type representing a SQL query is Query. My only (minor) frustration is that there is only really one way to create a Query (from a literal ByteString); so one cannot, for example, read the query in from a separately maintained .sql file and use that.
That’s it for Part I - look at for Part II coming soon! And as ever, if you spot anything incorrect, feedback is welcome.